
基本概念
- 字节:计算机数据存储的基本单元。比如1 Byte = 8 bits。
- 字符:信息单位,它是各种文字和符号的统称。
- 字符集:某个范围内字符的集合,比如ASCII有128个字符,GB2312有7445个字符。
- 字符码:字符集中每个字符的数字编号,比如ASCII有编号0至127。
- 字符编码:将字符集中的字符码映射为字节流的一种具体实现方案,比如ASCII字符编码规定使用单字节中低位的7bits去编码所有字符。「A -> 65 -> 0X41 -> b’01000001’」
- 编码(encode):将字符转换成字节流。
- 解码(decode):将字节流解析为字符。
ASCII码的历史
英文字符只用一个字节的存储空间就能表示,比如1 Byte = 8 bits 能代表256个字符。ASCII字符集由96个文字和32个控制符组成,只需要7位就能表示所有字符,剩下最高位被用作一些通讯系统的奇偶校验。由于西欧字符的数量远远超出ACSII码所能表达的范围,扩展ASCII码(EASCII)应运而生,EASCII由原来的ASCII码和一些表格符号,计算符号,希腊字母和拉丁符号组成。具体的字符范围是0x00~0x7F + 0x80 ~0xFF。代表性的字符集有CP437和ISO/8859-1。
GBK
多字节字符的编码GBF是为了解决汉字在计算机中的表达的问题。一般汉字使用双字节来编码的。代表性的字符集有GB312(共有6763个汉字)和GBK(共有27484个汉字)。
Unicode
Unicode是一种通用的编码方式,它是用十六进制数字表示的,一般在数字前面加上前缀U+,比如A的Unicode编码是「U+0041」,「中」的Unicode编码是「U+4E2D」。Unicode有两种格式:UCS-2和UCS-4。
- UCS-2:使用两个字节,共16个比特,最多可以表达65536个字符。
- UCS-4: 使用四个字节,共32个比特,最高位通常为0。理论上可以涵盖一切语言所用的符号。
Unicode是也有其局限性的。例如一个Unicode字符在网络上传输或者存储起来的时候,并不见得每个字符都需要两个字节,如字符A,统一使用两个字节会大大地浪费空间。另外,如何判断哪两个字节是表示一个字符,这需要不同的Unicode编码实现方法,如UTF-8和UTF-16。
UTF-8
Unicode Transformation Format,简称UTF-8,是一种变长的字符编码实现方式,可以根据具体情况用1至4个字符来表示一个字符。比如英文字符这些原本就可以用ASCII码表示的字符用UTF-8表示时就只需要一个字节的空间,和ASCII是一样的。对于多字节的字符,第一个字节的前n位都设为1,第n+1位设为0,后面字节的前面两位都设为10。剩下的二进制位全部用该字符的Unicode码填充。以「陶」为例,「陶」的Unicode编码是「U+9676」,对应的UTF-8十六进制范围是00000800~0000FFFF,这表明了「陶」用UTF-8表示时需要用3个字节来存储,「U+9676」的二进制表示是1001011001110110,填充到1110xxxx 10xxxxxx 10xxxxxx得到11101001 10011001 10110110,转换成十六进制是e999b6。以下是Unicode和UTF-8转换关系表(x字符表示码点占据的位)。
| 起始值 | 终止值 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|
| 0000 | 007F | 0xxxxxxx | |||||
| 0080 | 007FF | 110xxxxx | 10xxxxxx | ||||
| 0800 | FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 10000 | 1FFFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 200000 | 3FFFFFF | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 4000000 | 7FFFFFFF | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Python2编码
Python2默认编码是ASCII,所以在Python2中源代码文件必须显示地指定编码类型,否则但凡代码中出现有中文就会报语法错误。Python2中的字符串有两种类型,分别是str和unicode,它们都是继承自basestring类,而str类型的字符串的编码格式可以是ascii,utf-8,gbk等任何一种类型。
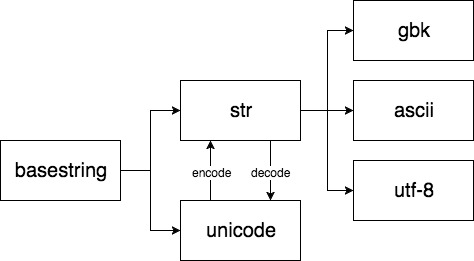
str与unicode转换
这两种类型的字符串之间的转换靠的就是decode和encode两个函数。encode负责将unicode编码成制定的字符编码,用语存储到磁盘或传输到网络中。而decode方法是根据指定编码方式解码后在应用程序中使用,所以从unicode转换到str用的是encode,从str类型转换到unicode则用decode。

UnicodeEncodeError或者UnicodeDecodeError的原因
这些错误的根本原因在于Python2默认是使用ASCII编码进行decode和encode操作。
案例I
12s = '你好' # str --> decodes = u'你好' # unicode --> encode案例II
当str类型与unicode类型的字符串混合使用时,str类型字符串会隐式地将str转换成unicode字符串。「python2默认会使用ascii编码来进行decode操作。」
案例Ⅲ
所有出现乱码的原因都可以归结为字符经过不同编码解码导致在编码过程种使用的编码格式不一致!比如utf-8编码的字符「陶」占用3个字节,解码成unicode后。如果再用gbk来解码后,只有两个字节长度了,最后出现了乱码问题,因此防止乱码的最好方式就是始终坚持使用同一种编码格式对字符进行编码和解码操作。

编码解码在Python中的实际应用
encode()函数
encode函数的声明:S.encode([encoding[,errors]]) -> object,作用是将str或者unicode编码成str,其中encoding参数指定的是编码结果字符串的编码类型,如果encoding没有指定的话,那么编码类型取sys.getdefaultencoding()。
decode()函数
decode函数的声明:S.decode([encoding[.errors]]) -> string or unicode,作用是将一个str对象解码成unicode对象,其中encoding参数设置是被解码字符串的解码类型,而返回unicode对象的默认编码是utf-8。